大家都在说同步IO、异步IO、阻塞IO、非阻塞IO,本人对其中的有些知识也是有些模糊,借此机会决定研究一下。
本文旨在澄清、说明和探讨 JAVA I/O的几点基本概念和知识,以及各种IO模型的优缺点,欢迎讨论。
JAVA NIO 模型
在探讨JAVA I/O模型之前,我们先来说一下Linux上的几种I/O模型及其区别。
Linux 网络 I/O 模型
首先,对一个IO的访问,数据首先会被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用进程的缓冲区。因此一个IO操作会经历两个阶段(如图):
- 等待数据准备(将数据拷贝到内核缓冲区)
- 将数据从内核拷贝到应用进程缓冲区
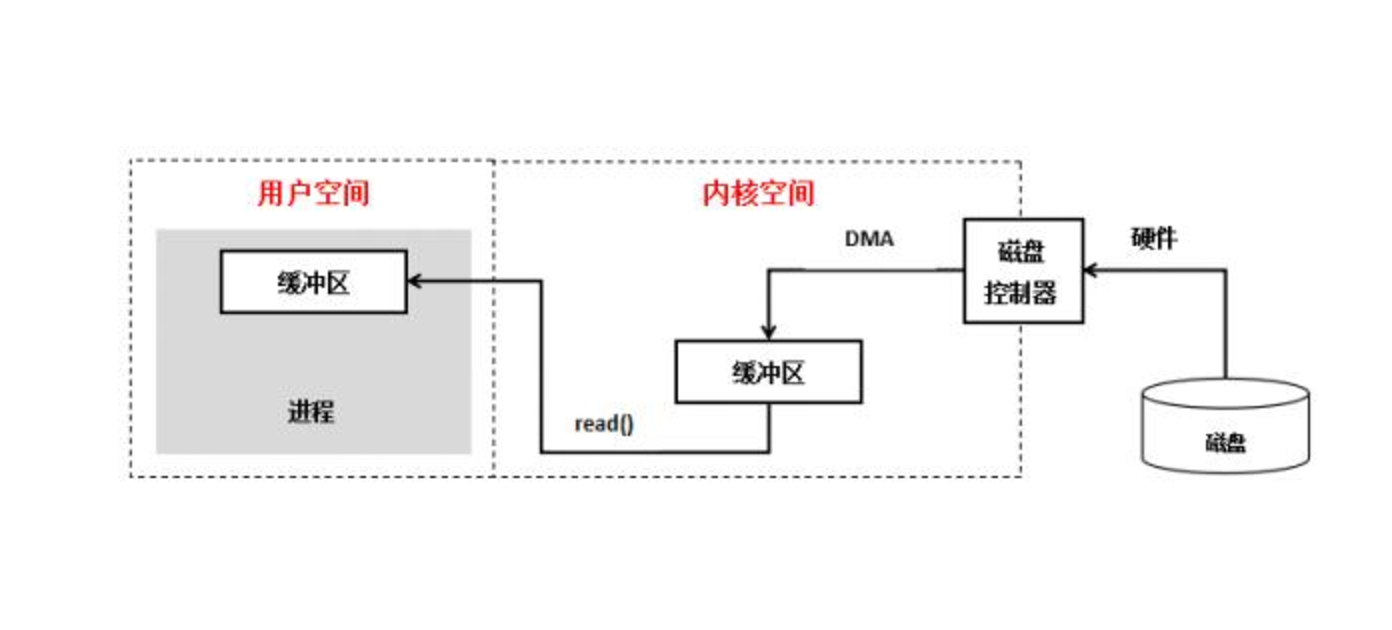
附:
1、 用户空间和内核空间
2、文件文件描述符 : Linux对文件的读写会返回一个filedescripeor(fd,文件描述符); 对一个socket的读写也会返回相应的描述符:socketfd(socket描述符)。
这些描述符就是一个数字,它指向内核为每一个进程所维护的该进程打开文件的记录表。
接下来看看Unix的I/O模型,Unix提供5中I/O模型有以下几种。
阻塞I/O模型
阻塞I/O模型是最常用的I/O模型, 在这个模型中,应用进程执行一个系统调用(recvfrom),其系统调用会一直阻塞,直到 数据包到达且被复制到应用进程的缓冲区或者发成错误才返回(解除阻塞)。 阻塞I/O模型的特点就是 进程从执行系统调用开始到返回的整个时间内都是被阻塞的,应用程序会一直等待直到收到系统响应(数据传输完成或发生错误)。
如下图所示: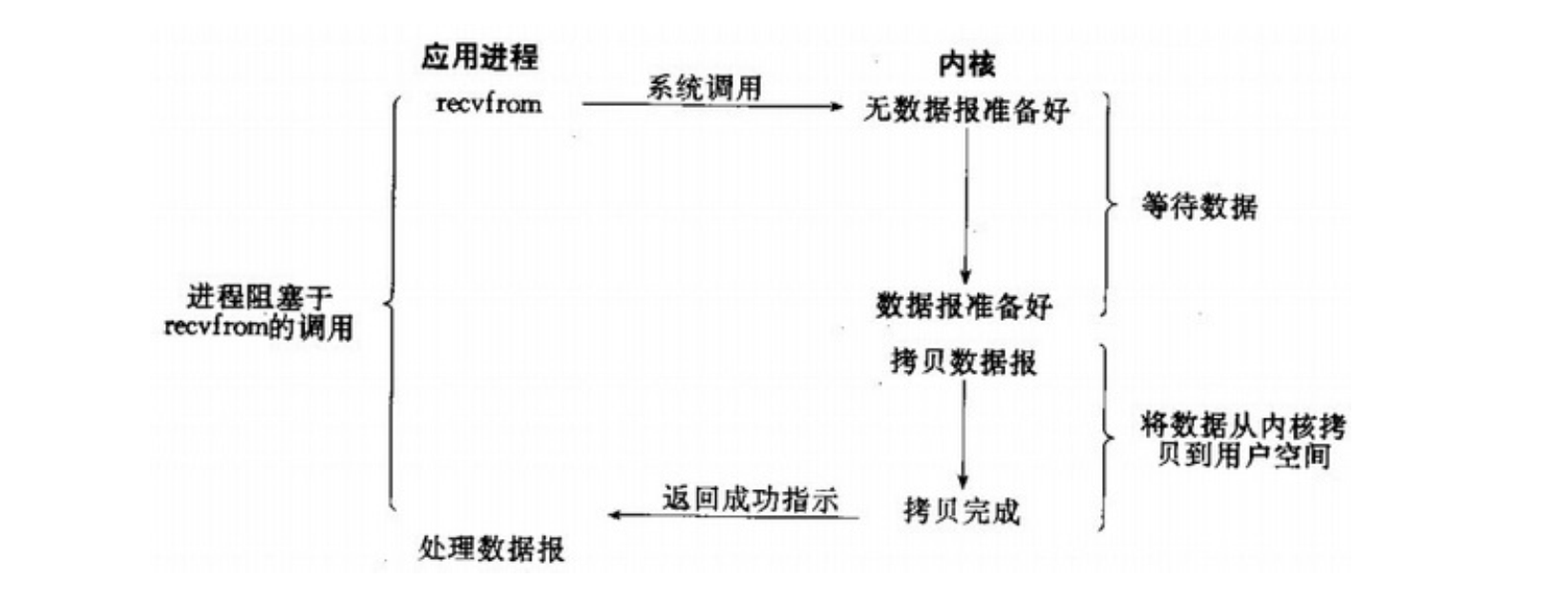
阻塞I/O模型在IO执行的两个阶段都是阻塞的。
使用阻塞I/O模式开发简单,适合用于实现对少量文件描述符进行IO操作、或者需要及时返回数据的应用;
但是同时对大量文件描述符进行IO操作时,可以利用多线程技术进行处理,但是会造成大量的线程开销,增加系统的维护工作量,扩展性能很差。
非阻塞I/O模型
这种模型其实是阻塞
I/O模型的一个变种。
recvfrom从用户空间的应用层到内核的时候,如果缓冲区没有数据的话,就直接返回一个EWOULDDBLOCK错误,也就是说非阻塞的recvfrom系统调用之后,进程并没有被阻塞,内核马上返回给进程(EAGAIN/EWOULDDBLOCK)。一般都是对非阻塞
I/O模型进行轮询检查这个状态,看内核是不是有数据到来。很显然,这样效率明显不高,因为应用程序需要进行忙碌等待,不断的轮训执行系统调用,上下文切换,CPU一直用在无谓的轮询上,消耗大量的CPU时间,最终降低整体数据吞吐量。需要注意的是:在数据拷贝过程中,进程仍然属于阻塞状态。
如下图所示: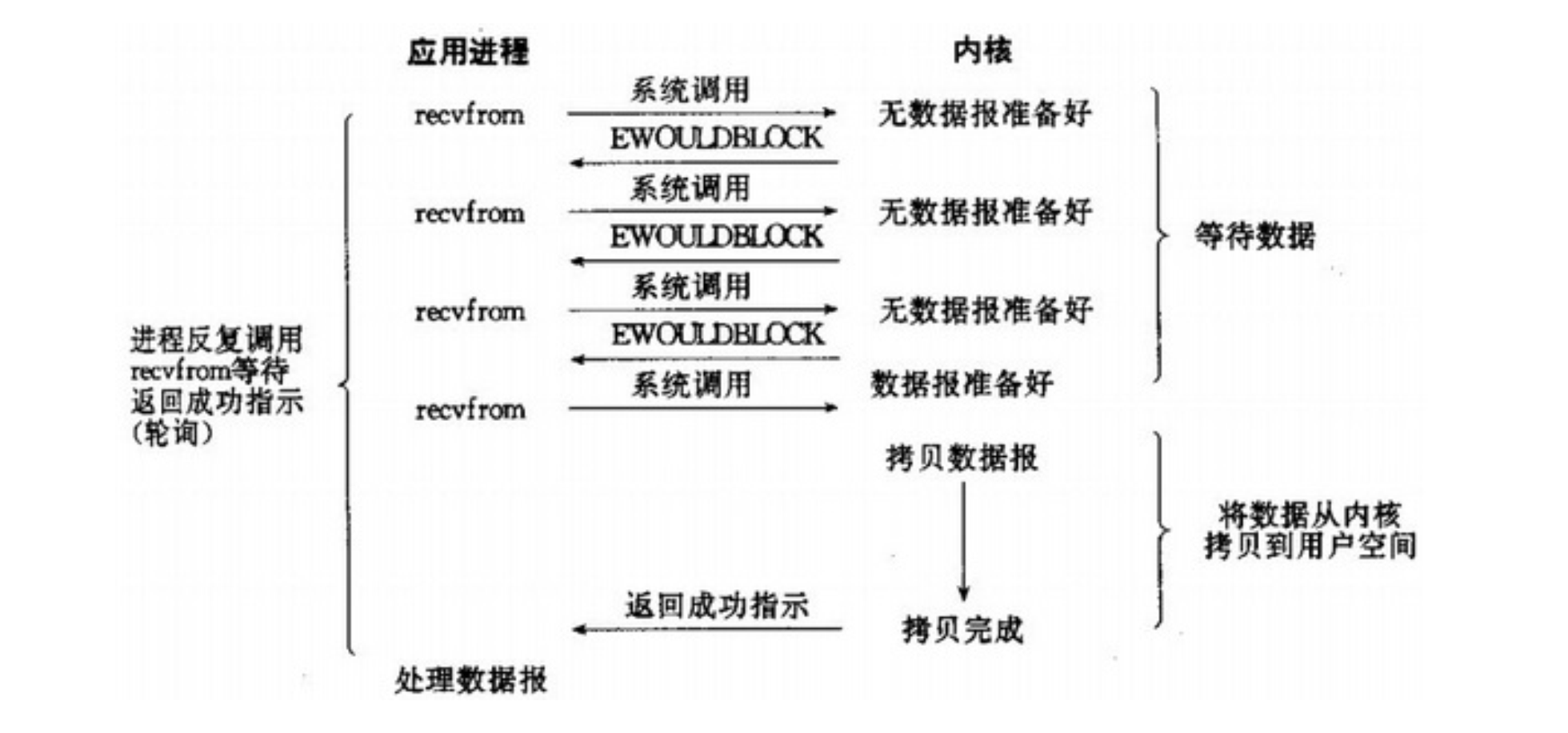
I/O 复用模型
IO复用模型 有几个特殊的系统调用(select、poll、epoll)函数。其基本原理就是,进程通过将一个或多个fd/socketfd传递给系统调用函数(select、poll、epoll),阻塞在select操作上,这样select/poll可以帮助我们侦测多个fd/socketfd是否处于就绪状态。当其中有一个数据准备就绪,就能返回通知用户进程可读,然后进程再调用 recvfrom 系统调用,将数据由内核拷贝到用户进程,注意这个过程 是 阻塞的。与阻塞
IO的区别是,此时的select不是等到socket数据全部到达再处理,而是只要有数据到达就会通知用户进程,然后用户进程来处理。
如下图所示。
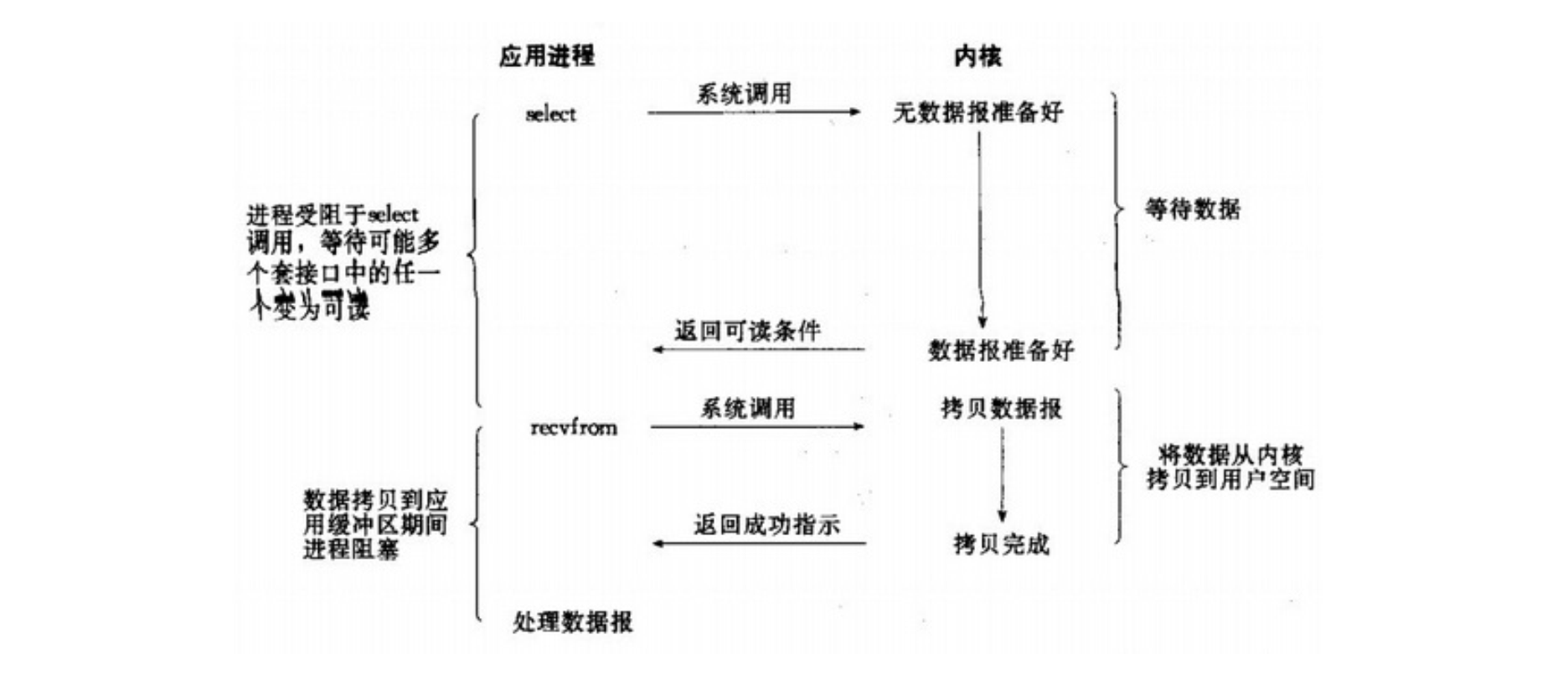
select/poll是顺序扫描fd/socketfd是否就绪,而且支持的 fd/socketfd 数量有限,因此它的使用受到一些限制。epoll是基于事件驱动方式代替顺序扫描,性能更高,当fd/socketfd就绪时,立即返回函数rollback。简单明了的说就是 相当于应用程序不用再轮训等待数据是否就绪,而是交给
select或poll或epoll, 在某个数据就绪时通知用户进程去操作。只不过select或poll是顺序扫描fd,epoll是基于事件驱动,效率更高。
I/O多路复用技术通过把多个I/O的阻塞服用到同一个select的阻塞上,从而使得系统在单线程的情况下可以同时处理多个客户端请求。与传统的多线程多进程模型对比,I/O多路复用模型的的最大优势是系统开销小,不需要创建和维护新的额外进程或线程,降低里系统的维护工作量,节省了系统资源。
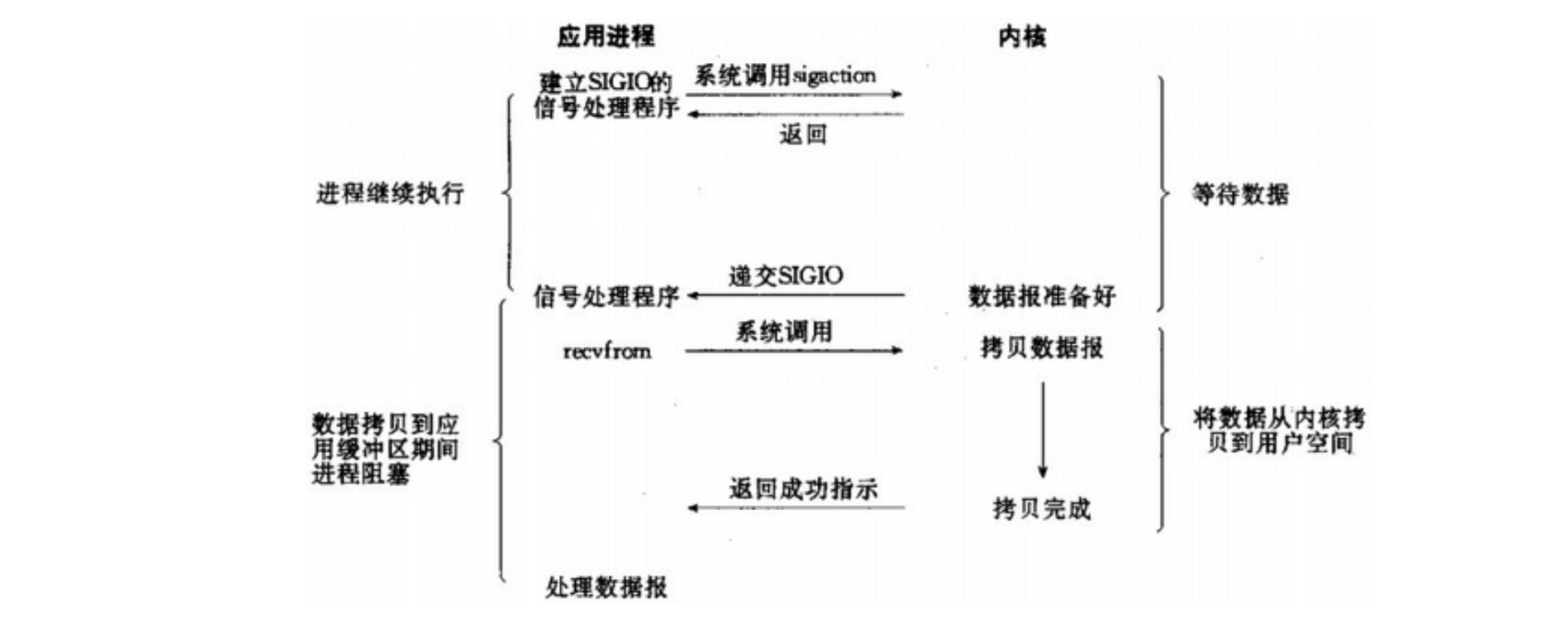
信号驱动I/O模型
首先开启套接口信号驱动
I/O功能,并且通过系统调用sigaction执行一个信号处理函数(此系统调用立即返回,进程继续工作,它是非阻塞的)。当有数据准备就绪时,就为该进程生成一个SIGIO信号,通过信号回调通知应用程序调用recvfrom来读取数据,并通知应用程序处理数据。
如下图所示:
异步 I/O
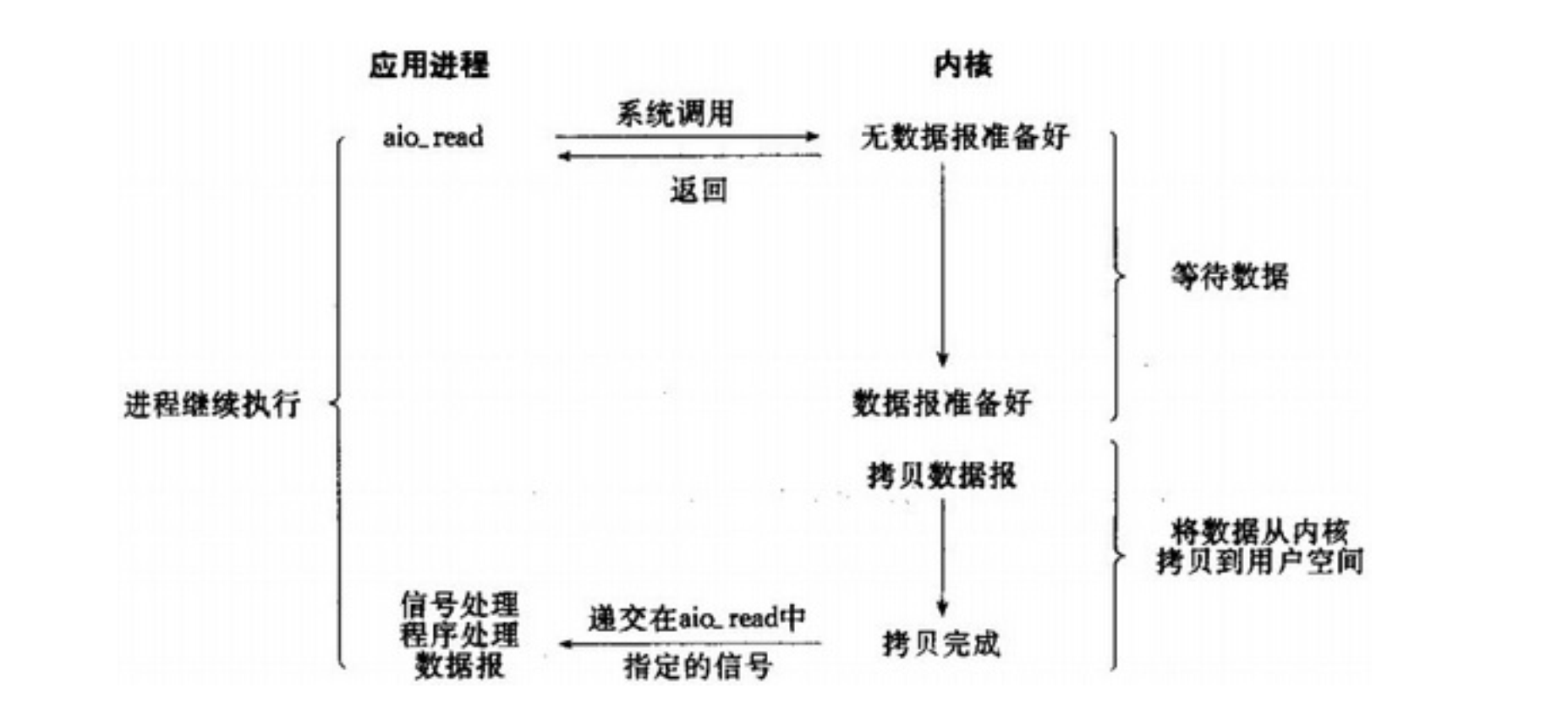
应用进程发起
aio_read操作后,会立刻返回,并让内核在整个操作完成后(包括将数据从内核空间复制到用户空间)通知用户进程,告知用户进程操作已完成。这种模式与信号驱动模式的区别是:信号驱动
I/O由内核通知用户进程何时可以开始一个I/O操作;异步I/O模型由内核通知用户进程I/O操作已经完成。
如下图所示:
这大概就是异步非阻塞IO的原型。
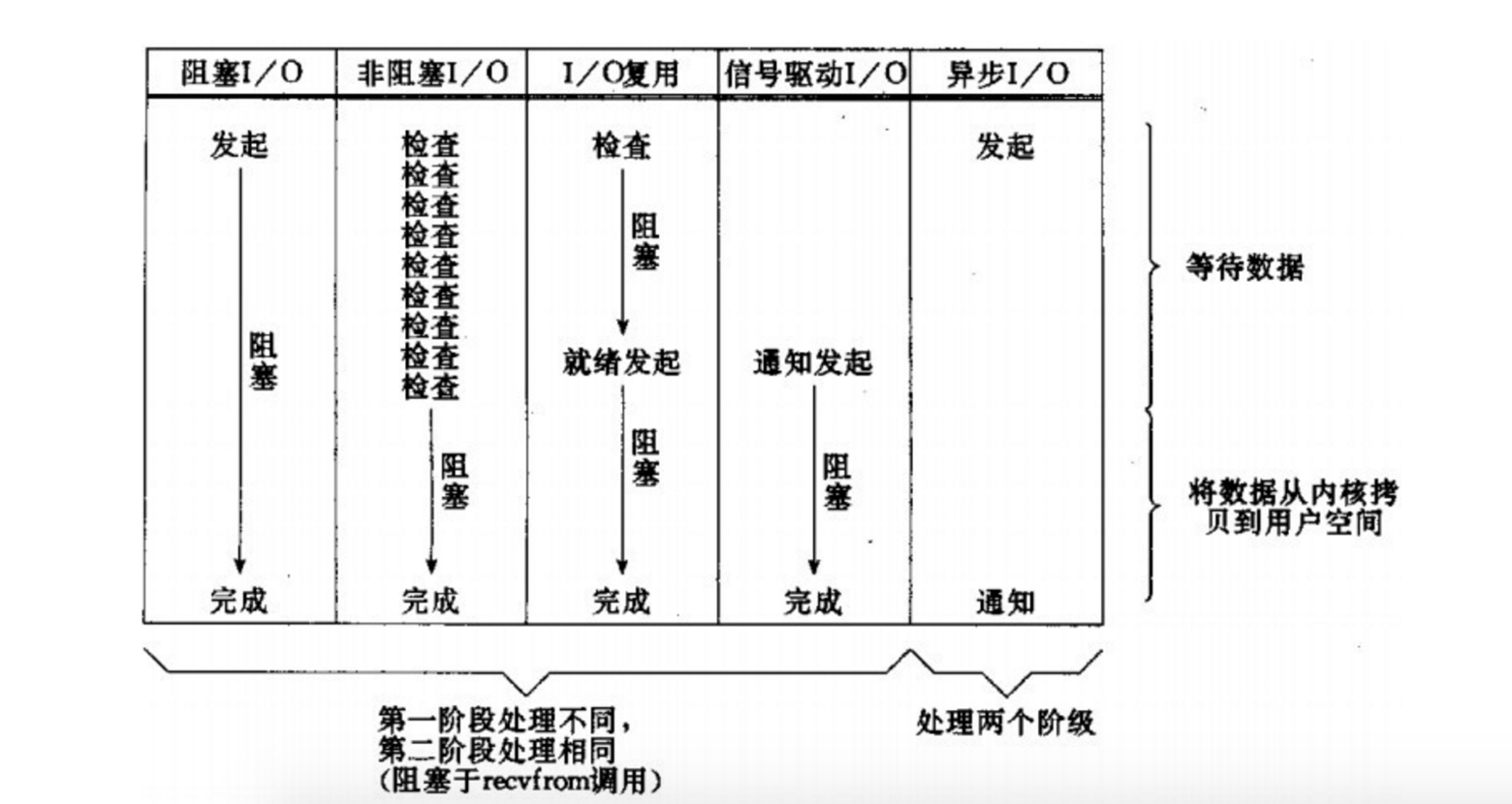
五中IO模型对比:
阻塞
I/O:进程一直阻塞,直到数据拷贝完成
非阻塞I/O: 通过进程反复轮询(多次系统调用,并马上返回);在数据拷贝的过程中,进程是阻塞的;I/O多路复用:主要是select,poll和epoll;对一个I/O端口,两次调用,两次返回,比阻塞I/O并没有什么优越性;关键是能实现同时对多个I/O端口进行监听;
信号驱动I/O:两次调用,两次返回;第一次调用立即返回,该过程非阻塞的。数据准备就绪后通知用户进程调用系统函数(recvfrom)来读取数据,期间进程是阻塞的;
异步I/O:数据拷贝的时候进程无需阻塞。数据的拷贝由内核完成后通知用户进程。其中前四
I/O模型都属于同步I/O模型范畴,只有第五种属于 异步I/O模型
JAVA NIO
JDK1.4推出之前,基于java的Socket通信都是采用 BIO模型(模型1.1), JDK1.4 NIO的出现才开始支持I/O多路复用模型(模型1.3),直到JDK7 才开始提供异步非阻塞模型(模型1.5)的支持。
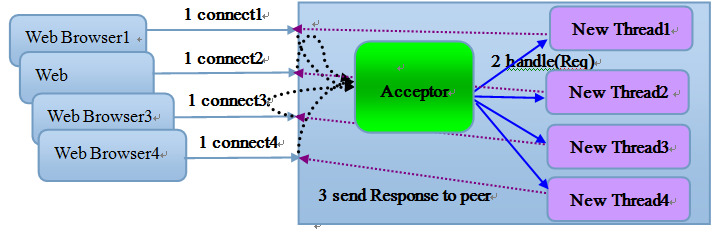
BIO
采用BIO通信模型的服务端,通常由一个独立的Acceptor线程负责监听客户端的连接,它接收到客户端连接之后为每个客户端创建一个新的线程进行链路处理,处理完成之后,通过输出流返回应答给客户端,线程销毁。这就是典型 请求一应答 通信模型。通信模型如下:
该模型的开发示例如下:
BioTimeServer.java
BioTimeServerHandler.java
BioTimeClient.java
运行
BioTimeServer和BioTimeClient后,你会发现 服务端BioTimeServer在调用ServerSocket.accept()方法时,会一直阻塞,直到有客户端连接才会返回,每个客户端连接过来后,服务端都会启动一个线程去处理该客户端的请求。同样,客户端BioTimeClient在调用InputStream.read()方法时 也是一直阻塞的,直到数据到来时(或超时)才会返回。该模型最大的问题就是每当有一个客户端请求接入时,服务端必须创建一个新的线程处理新接入的客户端链路,一个线程只能处理一个客户端连接。在高性能服务器应用领域,往往需要面向成千上万个客户端的并发链接,随着并发访问量的继续增大,系统将会发生线程堆栈溢出,创建新线程失败等问题,最终导致进程宕机或僵死,不能对外提供服务,这种模型显然无法满足高性能、高并发接入的应用场景。
不管是磁盘
I/O还是网络I/O,数据在写入OutputStream或者从InputStream读取时都有可能会阻塞。一旦有线程阻塞将会失去CPU的使用权,这在当前的大规模访问量和有性能要求情况下是不能接受的。虽然当前的网络I/O有一些解决办法,如一个客户端一个处理线程,出现阻塞时只是一个线程阻塞而不会影响其它线程工作。再比如: 为了减少系统线程的开销,采用线程池的办法来减少线程创建和回收的成本— 伪异步IO
伪异步I/O
伪异步I/O的后端通过一个线程池来处理多个客户端的请求接入,形成客户端个数M:线程池最大线程数N的比例关系,其中M可以远远大于N,通过线程池可以灵活的调配线程资源,设置线程的最大值,防止由于海量并发接入导致线程耗尽。如图,采用线程池 和任务队列实现伪异步I/O。
当有新的客户端接入的时候,将客户端的Socket封装成一个Task提交到线程池中进行处理,JDK的线程池维护一个消息队列和N个活跃线程对消息队列中的任务进行处理。由于线程池可以设置消息队列的大小和最大线程数,因此,它的资源占用是可控的,无论多少个客户端并发访问,都不会导致资源的耗尽和宕机。
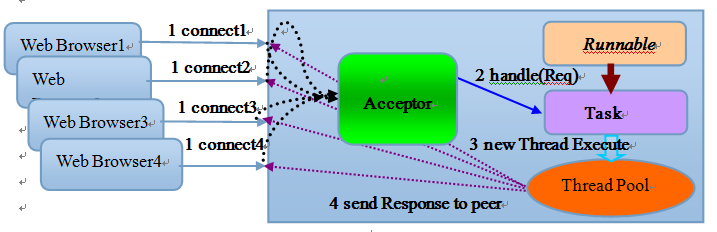
该模型的开发示例如下:TimeServerHandlerExecutePool.java
伪异步I/O通信框架实际上仅仅只是对之前I/O线程模型的一个简单优化,虽然采用了线程池实现,但是由于它底层的通信依然采用同步阻塞模型,因此无法从根本上解决问题。
试想如果出现一下几种情况时会发生什么
- 服务端处理慢,响应时间过长
- 队列积满
- 客户端连接超时
这其实是一个连锁反应,由于服务端处理缓慢,导致客户端响应变慢,此时将会出现大量的队列堆积,积满之后,入队列发生阻塞,此时就会出现大量的客户端连接超时,此时调用者会认为系统已经崩溃,无法接收新的请求消息。。
NIO
JDK1.4提供了对非阻塞IO(NIO)的支持,它是基于I/O多路复用模型实现的非阻塞I/O,底层是基于select/poll模型实现的,JDK1.5_update10版本对该模型进行优化,使用epoll替代了传统的select/poll,上层API并没有发生变化,极大的提升了NIO通信的性能。
其中引入了新的I/O类库和一些新的概念:
缓冲区Buffer:Buffer是一个对象,简单来说,它包含要写入或者要读出的数据。在NIO类库中,任何对NIO数据的读写,都是通过缓冲区进行操作的。通道Channel:通过Channel我们可以读取和写入数据到缓冲区。也可以这么说:通道用于在缓冲区和位于通道另一侧的实体(文件、套接字)之间有效的传输数据。
还有一点需要知道的是 : Channel和Stream的不同之处就在于Channel是全双工的,即双向的,可以用于读和写。
多路复用器Selector:就是上面(LinuxI/O多路复用模型)提到的多路复用器。Selector会不断的轮询注册在其上的Channel,如果某个Channel上面有新的TCP连接接入、读或者写事件, 这个Channel就处于就绪状态,会被Selector轮询出来,然后通过SelectorKey可以获得就绪的Channel,进行后续的I/O操作。
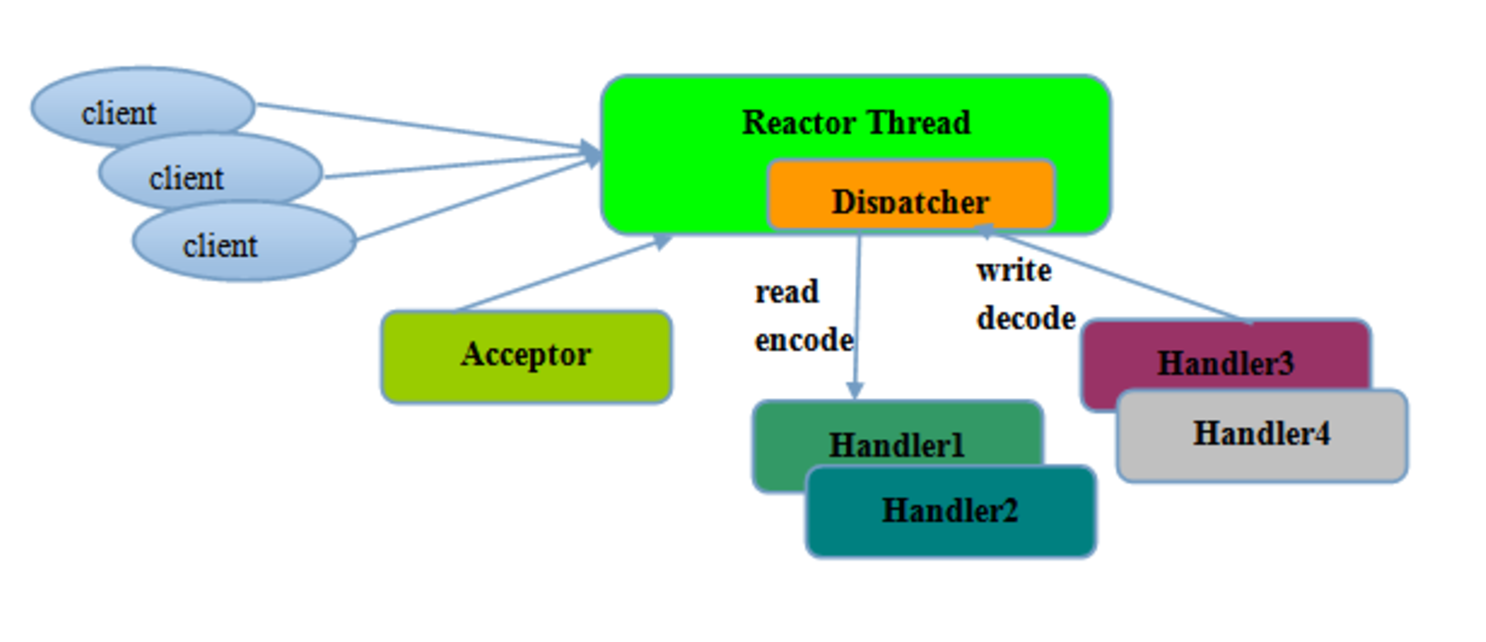
该模型的开发示例如下:
NioTimeServer.java
NioTimeClient.java
NioTimeClientHandle.java
我们不难发现BIO与NIO有如下不同之处:
- 编码复杂度很显然高与
BIO- 传统
IO(BIO)在 进行读写时,需要阻塞直到可读或写。而NIO客户端发起的连接操作是异步的,可以通过在多路复用器上注册OP_CONNECT等待后续结果,不需要像BIO那样被同步阻塞。NIO都是通过缓冲区Buffer进行读写操作的SocketChannel的读写是全双工且异步的,如果没有可读或可写的数据它不会同步等待,直接返回,这样IO通信线程就可以处理其它的链路,不需要同步等待这个链路可用- 从阻塞
I/O和 多路复用I/O的模型模型图中可以看出,他们并没有太大的区别,只是多一步 在Selector上注册连接/读/写事件(servChannel.register),以及调用select函数的额外操作,效率更差。
由于JDK的`Selector`在`Linux`等主流操作系统上通过`epoll`实现,它没有连接句柄数的限制(只受限于操作系统的最大句柄数或者对单个进程的句柄限制),这意味着一个`Selector`线程可以同时处理成千上万个客户端连接,而且性能不会随着客户端的增加而线性下降,因此,它非常适合做高性能、高负载的网络服务器。而在阻塞`I/O`模型中,必须通过多线程的方式才能达到这个目的。
在`JDK1.4`时,`Selector`是基于`I/O`多路复用模型的 `select/poll`实现的,在`JDK1.5`的时候,底层使用epoll模型对其进行性能优化,但是本质上还是非阻塞`I/O`。
###AIO
JDK1.7 又对NIO进行了升级,是很正的异步非阻塞I/O,它提供了 与Unix网络编程事件驱动IO对应的AIO,它不需要多路复用器Selector对注册的通过Channel进行轮询操作即可实现异步读写,从而简化了NIO编程。NIO是在有数据准备就绪后,就返回通知用户进程进行可读/写,然后用户进程再调用recvfrom系统调用,将数据由内核拷贝到用户进程。而 AIO是在 IO操作已经完成后,再给用户进程发出通知。因此AIO是非阻塞的。
该模型的开发示例如下:
AioTimeServer.java
AioTimeServerHandler.java
AcceptCompletionHandler.java
ReadCompletionHandler.java
AioTimeClient.java
AioTimeClientHandler.java
参考 :
1、Scalable IO in Java
2、《Unix网络编程》